Last year I spent about a third of my time in China. I didn’t post many pictures, I often travelled alone, and I had a difficult time succinctly summarizing what China is like. As a result, I don’t think many people know much about my time in China.
Roughly every 6 weeks I went to China for 2 weeks, throughout most of 2014. I flew Hainan Airlines a few times (which was nice because those flights are on Dreamliners) but ultimately settled in on a regular Delta route, and switched loyalty programs from United to Delta as a result of all of those 11-hour trips. Each time I visited, things got easier to the point where it became a routine.
Before leaving I’d swap out my regular wallet for my “China Wallet”. The flight to Beijing is about 11 hours from Seattle, enough to easily watch several movies. And, in my case, eventually get through most of the Delta movies worth watching and start bringing my own.
China Standard Time is GMT+8, so it’s either 15 or 16 hours ahead of the West coast depending on our daylight savings. When you fly West to China you cross the International Date Line and lose a day. And, the flight itself takes 11 hours. So… what that boils down to is that when you fly there, you land the next day, a few hours later than when you took off. I always prefer to fly out in the evening so that as soon as I landed in Beijing, I could go to bed. When you fly back, you land the same day, a few hours before you took off. I liked leaving in the morning from China, and would land and go straight to work from the airport. Seeing two sunrises on the same day was strange at first.
My home was always the Holiday Inn Express Beijing Huacai. Truth be told, I really liked it. I got to know many of the people there, I loved the breakfast buffet even if it got tired after 10 consecutive days, and it really did eventually feel like home. On Christmas, I brought everyone candy canes.
It’s big
Having travelled mostly to Europe and South America, I really never appreciated this fact:
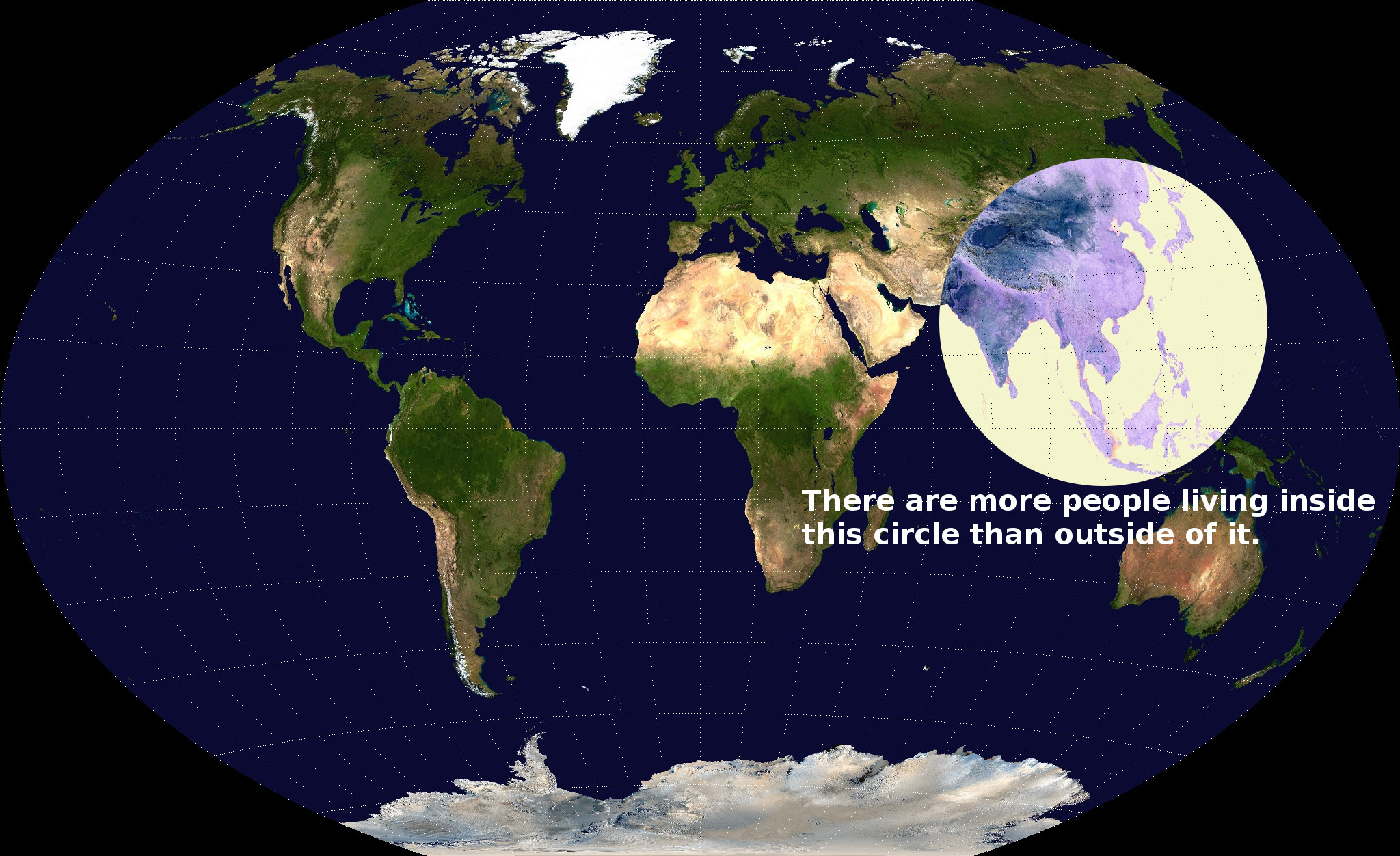
That is to say, when I used to think of “the rest of the world” the places that came to mind are not actually the places that most of the world lives. There are countless mind-boggling facts about the scale of China (and India). There are 15 cities with more than 10 million people (more populous than New York City). There are 170 cities with more than a million people. The US has 10.
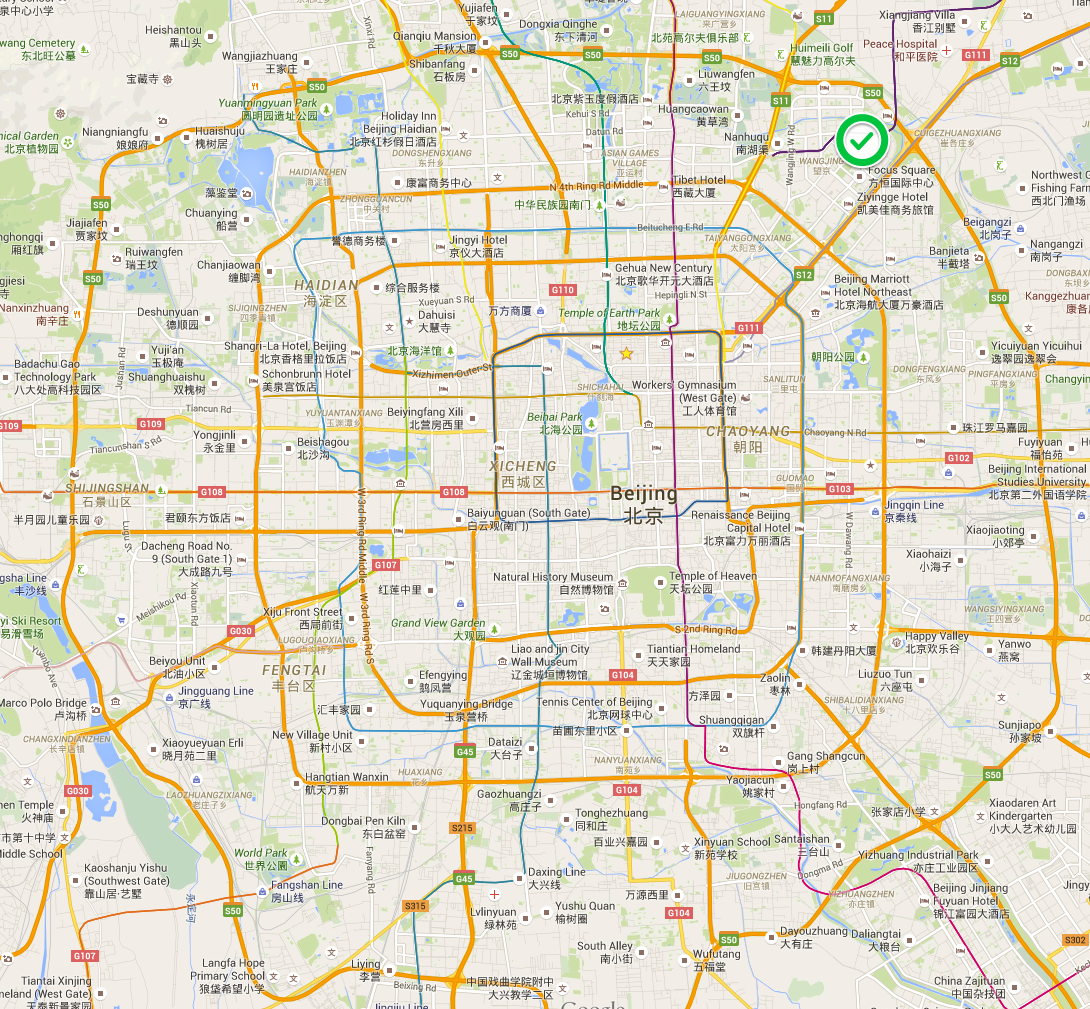
Beijing itself is built as a set of concentric circles (“rings”) around the center of the city. The center of the city is The Forbidden City and people don’t live there. I lived up near the green checkmark. To get from there to the forbidden city by taxi would take about an hour. I never felt like I saw “a condo building” – a building by itself didn’t even seem to count as meaningful residential construction. At a minimum, I’d see 4 identical condo towers, sometimes 8. It’s a big city.
Information
Yes, Facebook, Twitter, and Google are all blocked. The Great Firewall of China exists, and your only way around it is with either a VPN or a foreign SIM card. In fact, a regular VPN won’t even do the trick, you need one that supports additional encryption/scrambling because the GFW can block things based purely on encrypted traffic patterns. I used Astrill and it was great.
The TV in the hotel has a few English channels, including the CNN International channel. However, whenever they would do a story about China, the TV would go black.
In China, you’d use Baidu instead of Google, Weibo instead of Twitter, and WeChat instead of Facebook. You’d shop at Taobao (by Alibaba) or JD instead of Amazon. These aren’t perfect analogs, as the different services have different featuresets, but between them they cover the same sorts of things the US sites do for the western world. These services all operate within the rules of the Chinese government, and implement the required censorship and monitoring. In China you have a vastly different view of the Internet than the rest of the world.
The pollution
 People asked me about the pollution… at times, it was quite bad. This is a photo taken from the window of my hotel one morning. I didn’t wear a mask, but many people did. Fortunately, being a 2-block walk from work meant I could stay indoors when the air got this bad.
People asked me about the pollution… at times, it was quite bad. This is a photo taken from the window of my hotel one morning. I didn’t wear a mask, but many people did. Fortunately, being a 2-block walk from work meant I could stay indoors when the air got this bad.
There are some exceptionally clear days, but overall I think Beijing has a smell to it, that I eventually got used to. The people who live in Beijing and other big cities are aware of the problem and don’t like it. Children get sick and some people choose to move their families to less polluted towns.
The language
Mandarin is by far the most-popular natively spoken language on Earth.
Unfortunately, it is hard to learn. Since it doesn’t have a phonetic alphabet, you basically have to learn how to speak and how to read as two independent activities. Foolishly, I focused on learning how to read, so I had a decent shot at parsing menus. This came in handy when I could point at things, and was useless when I needed to say them out loud. I used Memrise for this, and it was pretty fun. The Chinese characters have interesting origins and it’s fun to try to come up with mnemonics for some of them. For example: 牛肉. 牛 looks a bit like a cow with it’s head over a fence, and means cow. 肉 looks like 2 steaks on a pan, and means meat. Together, it’s the word for beef.
I did not to a good job of focusing on learning the language. I know many people who have done it, but for me it was difficult to prioritize particularly given how often I was coming back to the US.
The food
I tried to eat adventurously. The only thing I really wouldn’t go near were the spiders. Here are some of the more unusual things I ate:

Rabbit Heads

Snails

Tried scorpion (but didn’t touch spiders)

Jellyfish

Chicken feet

Pigeon
Some food seemed adventurous initially, like the fact that virtually all fish is served whole, but it just became normal. I loved the Chinese food. It bears almost no resemblance to American Chinese food.

Spicy Fish

Steamed Buns (Baozi. My favorite.)

Chinese Hamburgers

Hotpot

Spicy beef (or pork)
The people
I met a lot of fantastic people in China – both expats and native. On only one occasion did someone come up and ask to take a picture with me, and that was when we were in the Forbidden City on the weekend. People in big cities like Beijing see plenty of foreigners these days, but The Forbidden City is a tourist destination that attracts people from all around China (you can compare it to people from around the US going to Washington, DC).
The most challenging parts of interactions were (obviously) the language, and the customs. People are generally forgiving that I don’t know their customs, ex. sometimes I’d forget and offer/accept something with one hand instead of two. Similarly, I’d find myself forgetting that they don’t share western customs – holding a door open, saying “bless you” when you sneeze, etc. It’s different enough that I never really felt like I was fitting in. Unlike Shanghai which is uniquely international and pretty easy for Westerners, Beijing is a very Chinese city. Most people don’t speak English. Of the people who do speak English, most don’t speak it much better than I speak French (ie. they learned it in school but don’t have much excuse to use it). So, that makes a lot of interactions hard.
I eventually did a fine job at navigating the “happy path” of interactions, but I would get in trouble if things went off course. For example, I can pay a bill at a restaurant, but trouble strikes if they have an issue with the credit card. Or, if I’m checking out at the grocery store and they ask me anything other than “do you want a bag?” by pointing at it.
The sights
Unfortunately I didn’t see much of the country overall. Virtually all of my time was in Beijing, with the exception of one weekend in Shanghai, and one trip to the Great Wall. The urban and rural parts of China are drastically different, and I wish I’d had more exposure to the rural parts.
Protip: Discover Cards are compatible with China Unionpay. It’s the most compelling reason to get a Discover Card.
It’s different here
It’s always hard for me to summarize what it’s like in China. One thing that really struck me is that people didn’t look at me as “American” – I was just “Western.” In other words, the differences are so vast that knowing I’m from the West is enough to have a feel for my general worldview, my common customs, the food I typically eat, the fact that I probably don’t speak Chinese, and probably do speak English. Relative to China, Westerners are alike and the differences between Western countries are minor.
I was fortunate enough to get one of the newer 10-year visas before I stopped traveling for business. I hope I’ll have the opportunity to make further use of it.